A powerful development environment for Java-based programming is Eclipse. Eclipse is a free, open-source IDE. It supports multiple languages through a plugin interface, with special attention paid to Java. Tools designed for working with Hadoop can be integrated into Eclipse, making it an attractive platform for Hadoop development. In this section we will review how to obtain, configure, and use Eclipse.
Downloading and Installing
Note: The most current release of Eclipse is called Ganymede. Our testing shows that Ganymede is currently incompatible with the Hadoop MapReduce plugin. The most recent version which worked properly with the Hadoop plugin is version 3.3.1, "Europa." To download Europa, do not visit the main Eclipse website; it can be found in the archive site http://archive.eclipse.org/eclipse/downloads/ as the "Archived Release (3.3.1)."
The Eclipse website has several versions available for download; choose either "Eclipse Classic" or "Eclipse IDE for Java Developers."
Because it is written in Java, Eclipse is very cross-platform. Eclipse is available for Windows, Linux, and Mac OSX.
Installing Eclipse is very straightforward. Eclipse is packaged as a .zip file. Windows itself can natively unzip the compressed file into a directory. If you encounter errors using the Windows decompression tool (see [1]), try using a third-party unzip utility such as 7-zip or WinRAR.
After you have decompressed Eclipse into a directory, you can run it straight from that directory with no modifications or other "installation" procedure. You may want to move it into C:\Program Files\Eclipse to keep consistent with your other applications, but it can reside in the Desktop or elsewhere as well.
Installing the Hadoop MapReduce Plugin
Hadoop comes with a plugin for Eclipse that makes developing MapReduce programs easier. In the hadoop-0.18.0/contrib/eclipse-plugin directory on this CD, you will find a file named hadoop-0.18.0-eclipse-plugin.jar. Copy this into the plugins/ subdirectory of wherever you unzipped Eclipse.
Making a Copy of Hadoop
While we will be running MapReduce programs on the virtual machine, we will be compiling them on the host machine. The host therefore needs a copy of the Hadoop jars to compile your code against. Copy the /hadoop-0.18.0 directory from the CD into a location on your local drive, and remember where this is. You do not need to configure this copy of Hadoop in any way.
Running Eclipse
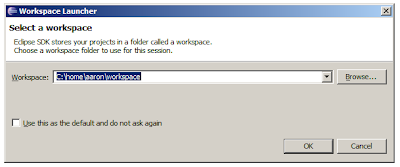
Navigate into the Eclipse directory and run eclipse.exe to start the IDE. Eclipse stores all of your source projects and their related settings in a directory called a workspace.
Upon starting Eclipse, it will prompt you for a directory to act as the workspace. Choose a directory name that makes sense to you and click OK.
eclipse-workspace
Configuring the MapReduce Plugin
In this section, we will walk through the process of configuring Eclipse to switch to the MapReduce perspective and connect to the Hadoop virtual machine.
Step 1: If you have not already done so, start Eclipse and choose a workspace directory. If you are presented with a "welcome" screen, click the button that says "Go to the Workbench." The Workbench is the main view of Eclipse, where you can write source code, launch programs, and manage your projects.
Step 2: Start the virtual machine. Double-click on the image.vmx file in the virtual machine's installation directory to launch the virtual machine. It should begin the Linux boot process.
Step 3: Switch to the MapReduce perspective. In the upper-right corner of the workbench, click the "Open Perspective" button, as shown in Figure 3.4:
Select "Other," followed by "Map/Reduce" in the window that opens up. At first, nothing may appear to change. In the menu, choose Window * Show View * Other. Under "MapReduce Tools," select "Map/Reduce Locations." This should make a new panel visible at the bottom of the screen, next to Problems and Tasks.
Step 4: Add the Server. In the Map/Reduce Locations panel, click on the elephant logo in the upper-right corner to add a new server to Eclipse.
You will now be asked to fill in a number of parameters identifying the server. To connect to the VMware image, the values are:
Location name: (Any descriptive name you want; e.g., "VMware server")
Map/Reduce Master Host: (The IP address printed at startup)
Map/Reduce Master Port: 9001
DFS Master Port: 9000
User name: hadoop-user
Next, click on the "Advanced" tab. There are two settings here which must be changed.
Scroll down to hadoop.job.ugi. It contains your current Windows login credentials. Highlight the first comma-separated value in this list (your username) and replace it with hadoop-user.
Next, scroll further down to mapred.system.dir. Erase the current value and set it to /hadoop/mapred/system.
When you are done, click "Finish." Your server will now appear in the Map/Reduce Locations panel. If you look in the Project Explorer (upper-left corner of Eclipse), you will see that the MapReduce plugin has added the ability to browse HDFS. Click the [+] buttons to expand the directory tree to see any files already there. If you inserted files into HDFS yourself, they will be visible in this tree.
Downloading and Installing
Note: The most current release of Eclipse is called Ganymede. Our testing shows that Ganymede is currently incompatible with the Hadoop MapReduce plugin. The most recent version which worked properly with the Hadoop plugin is version 3.3.1, "Europa." To download Europa, do not visit the main Eclipse website; it can be found in the archive site http://archive.eclipse.org/eclipse/downloads/ as the "Archived Release (3.3.1)."
The Eclipse website has several versions available for download; choose either "Eclipse Classic" or "Eclipse IDE for Java Developers."
Because it is written in Java, Eclipse is very cross-platform. Eclipse is available for Windows, Linux, and Mac OSX.
Installing Eclipse is very straightforward. Eclipse is packaged as a .zip file. Windows itself can natively unzip the compressed file into a directory. If you encounter errors using the Windows decompression tool (see [1]), try using a third-party unzip utility such as 7-zip or WinRAR.
After you have decompressed Eclipse into a directory, you can run it straight from that directory with no modifications or other "installation" procedure. You may want to move it into C:\Program Files\Eclipse to keep consistent with your other applications, but it can reside in the Desktop or elsewhere as well.
Installing the Hadoop MapReduce Plugin
Hadoop comes with a plugin for Eclipse that makes developing MapReduce programs easier. In the hadoop-0.18.0/contrib/eclipse-plugin directory on this CD, you will find a file named hadoop-0.18.0-eclipse-plugin.jar. Copy this into the plugins/ subdirectory of wherever you unzipped Eclipse.
Making a Copy of Hadoop
While we will be running MapReduce programs on the virtual machine, we will be compiling them on the host machine. The host therefore needs a copy of the Hadoop jars to compile your code against. Copy the /hadoop-0.18.0 directory from the CD into a location on your local drive, and remember where this is. You do not need to configure this copy of Hadoop in any way.
Running Eclipse
Navigate into the Eclipse directory and run eclipse.exe to start the IDE. Eclipse stores all of your source projects and their related settings in a directory called a workspace.
Upon starting Eclipse, it will prompt you for a directory to act as the workspace. Choose a directory name that makes sense to you and click OK.
eclipse-workspace

Configuring the MapReduce Plugin
In this section, we will walk through the process of configuring Eclipse to switch to the MapReduce perspective and connect to the Hadoop virtual machine.
Step 1: If you have not already done so, start Eclipse and choose a workspace directory. If you are presented with a "welcome" screen, click the button that says "Go to the Workbench." The Workbench is the main view of Eclipse, where you can write source code, launch programs, and manage your projects.
Step 2: Start the virtual machine. Double-click on the image.vmx file in the virtual machine's installation directory to launch the virtual machine. It should begin the Linux boot process.
Step 3: Switch to the MapReduce perspective. In the upper-right corner of the workbench, click the "Open Perspective" button, as shown in Figure 3.4:
Select "Other," followed by "Map/Reduce" in the window that opens up. At first, nothing may appear to change. In the menu, choose Window * Show View * Other. Under "MapReduce Tools," select "Map/Reduce Locations." This should make a new panel visible at the bottom of the screen, next to Problems and Tasks.
Step 4: Add the Server. In the Map/Reduce Locations panel, click on the elephant logo in the upper-right corner to add a new server to Eclipse.
You will now be asked to fill in a number of parameters identifying the server. To connect to the VMware image, the values are:
Location name: (Any descriptive name you want; e.g., "VMware server")
Map/Reduce Master Host: (The IP address printed at startup)
Map/Reduce Master Port: 9001
DFS Master Port: 9000
User name: hadoop-user
Next, click on the "Advanced" tab. There are two settings here which must be changed.
Scroll down to hadoop.job.ugi. It contains your current Windows login credentials. Highlight the first comma-separated value in this list (your username) and replace it with hadoop-user.
Next, scroll further down to mapred.system.dir. Erase the current value and set it to /hadoop/mapred/system.
When you are done, click "Finish." Your server will now appear in the Map/Reduce Locations panel. If you look in the Project Explorer (upper-left corner of Eclipse), you will see that the MapReduce plugin has added the ability to browse HDFS. Click the [+] buttons to expand the directory tree to see any files already there. If you inserted files into HDFS yourself, they will be visible in this tree.
Hi,
ReplyDeleteI am using VM image hadoop-appliance-0.18.0.vmx and an eclipse plug-in
of hadoop. I have followed all the steps in this tutorial:
http://public.yahoo.com/gogate/hadoop-tutorial/html/module3.html. My
problem is that I am not able to browse the HDFS. It only shows an
entry "Error:null". Upload files to DFS, and Create new directory fail. Any
suggestions? I have tried to chang all the directories in the hadoop
location advanced parameters to "/tmp/hadoop-user", but it did not
work.
Also, the tutorials mentioned a parameter "hadoop.job.ugi" that needs
to be changed, but I could not find it in the list of parameters.
I have the same problem.. let me know if you found a solution. thanks
Deletei had the same problem....i restarted vm and eclipse....and then i clicked on advanced tab and found hadoop.job.ugi....it was set to host user and you have to change it to hadoop-user.....
DeletePS...use eclipse europa...i tried with juno but couldnt connect
did you find any solution? I have the same problem with eclipse europa...
DeleteThis problem usually arises when you are working on windows environment.. The cause of the problem will be Cygwin is not installed or not properly installed.
DeleteDownload the Cygwin.exe file and run it.
It's not all.. After cygwin is installed successfully, you have to add the path of cygwin bin directory (e.g C:\cygwin\bin)to the environmental variable..
That's all now restart the virtual machine and eclipse and click on the DFS Locations on project explorer and try to explore the files.. You will get a connection error message..
Now try to find the hadoop.job.ugi, you will it..
I have done all those. i even set hadoop.job.ugi. But I got error as Call failed as local exception. Can anyone suggest a solution for my problem pls..
DeleteUnfortunately this problem also arises when using mac osx. Kindly let me know if you find a solution
DeleteTo fix this, go to "\workspace\.metadata\.plugins\org.apache.hadoop.eclipse\locations". Here open the XML file and just add the property "hadoop.job.ugi" with value "hadoop-user,ABC" and then restart your eclipse. It worked for me.
DeleteI too ran into the same issue. I installed redhad cgywin and updated the "Path" environment variable with path to cgywin/bin (C:\rhcygwin\bin). Then my eclipse dfs locations was able to connect to hadoop on the virtual machine. once that is successful i saw the option "hadoop.job.ugi". the link v-lad.org/Tutorials/Hadoop/00%20-%20Intro.html in the post above describes installing cgywin.
ReplyDeleteNote: I am running the hadoop vm on windows vista.
I had same problem with Windows 7. The reason was cygwin was not installed on my pc. There are some problems with cygwin on Win 7, after installing Cygwin, "cygwin sshd" service will not start. I found a fix (http://www.kgx.net.nz/2010/03/cygwin-sshd-and-windows-7/comment-page-1/) in net & now my pc(Windows 7 - 32 bit) is ready with Yahoo Dev N/w Hadoop VM (hadoop-0.18.0) + Eclipse (Juno).
ReplyDeleteThis comment has been removed by the author.
ReplyDeleteThis comment has been removed by the author.
ReplyDeleteI installed sshd using these instructions:
ReplyDeletehttp://docs.oracle.com/cd/E24628_01/install.121/e22624/preinstall_req_cygwin_ssh.htm
I started it:
net start sshd
Then, per http://hadoop.6.n7.nabble.com/Eclipse-plugin-td8156.html, in the conf/hadoop-site.xml file in the hadoop download from the tutorial, i.e., hadoop-0.18.0/conf/hadoop-site.xml
I added these lines in the preexisting block:
<property>
<name>fs.default.name</name>
<value>hdfs://<ip_address>:9000</value>
</property>
<property>
<name>mapred.job.tracker</name>
<value><ip_address>:9001</value>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
I then shut down the instance of Hadoop running in the virtual machine via
./stop-hadoop
then shutdown the virtual machine via
sudo poweroff
exited out of Eclipse
Restarted Eclipse, but from the Cygwin command line per http://hadoop.6.n7.nabble.com/Eclipse-plugin-td8156.html
Restarted the VMware Player and opened the virtual machine, and started hadoop via the "./start-hadoop" command from the tutorial.
Then, I deleted and recreated the VMware server in Eclipse. After that, the hadoop.job.ugi entry still wasn't there, HOWEVER, from the project explorer, I right clicked on the VMware server, and selected refresh, and then reconnect. Some entries then appeared below (a folder named "(2)", with some subfolders "hadoop (1)" with its own subfolder "mapred (1)", and another subfolder below "(2)" named "user (1)", and below that, "hadoop-user (0)". Now, when I right click in the Map/Reduce Locations on VMware server and select "Edit hadoop location", then "Advanced parameters", then, finally, the hadoop.job.ugi entry showed up.
Thanks dude.
ReplyDeleteHadoop Training in Chennai
Recording to this article excellent.i hope learn to lot of hadoop very useful for my projects.
ReplyDeleteHadoop Training in Chennai
This is Excellent reviews.thanks for that.
ReplyDeleteThanks to Share the QTP Material for Freshers,
ReplyDeleteqtptrainingchennai
ReplyDeletereviews-complaints-testimonials